Coletando dados do IBGE com Python e SIDRA
O IBGE possui um banco de pesquisas e suas tabelas estatísticas que podem ser acessadas através do SIDRA (Sistema IBGE de Recuperação Automática) .
Podem ser selecionadas as seguintes áreas de pesquisa:
- Indicadores
- População
- Economia
- Meio Ambiente
Através desta ferramenta conseguimos acessar diversas pesquisas.
Entre elas temos a Pesquisa Nacional por Amostra de Domicílios Contínua Anual - PNADC/A
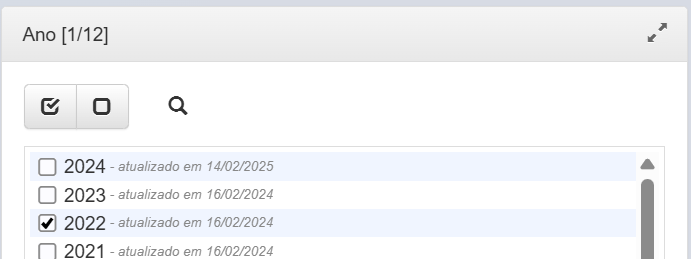
onde selecionamos os dados de 2022 na nossa pesquisa.
 A interface da SIDRA solicita a informação de alguns dados através de formulário para delimitar/filtrar o universo desejado da pesquisa:
A interface da SIDRA solicita a informação de alguns dados através de formulário para delimitar/filtrar o universo desejado da pesquisa:
- Informação do ano
-
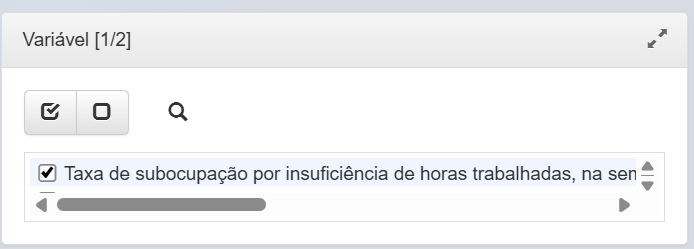
solicita a informação da variável desejada
-
nível territorial
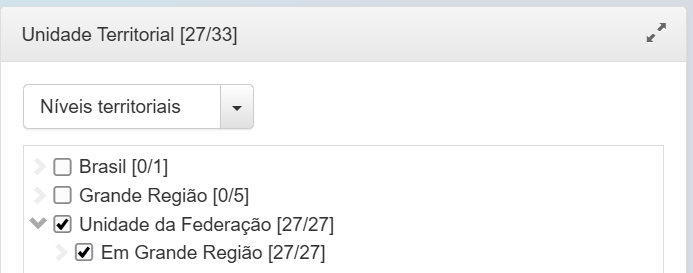
Após é possível: visualizar, fazer o download, determinar algumas opções de visualização
(notas de rodapé, exibição de códigos, ...).
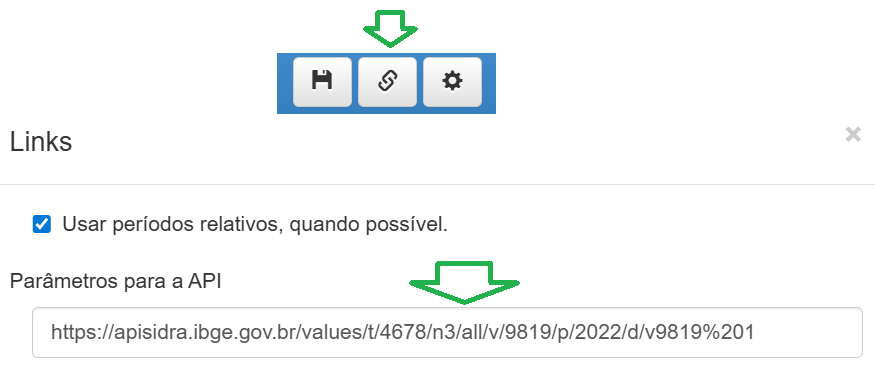
Em links de compartilhamento apresenta a url, baseada nos dados informados no formulário de filtro,
que foi utilizada para consumir a API e obter os dados da tabela desejada.
-
botões visualizar ...

-
salvar o quadro, links de compartilhamento e opções avançadas.
-
retorno no formato XML

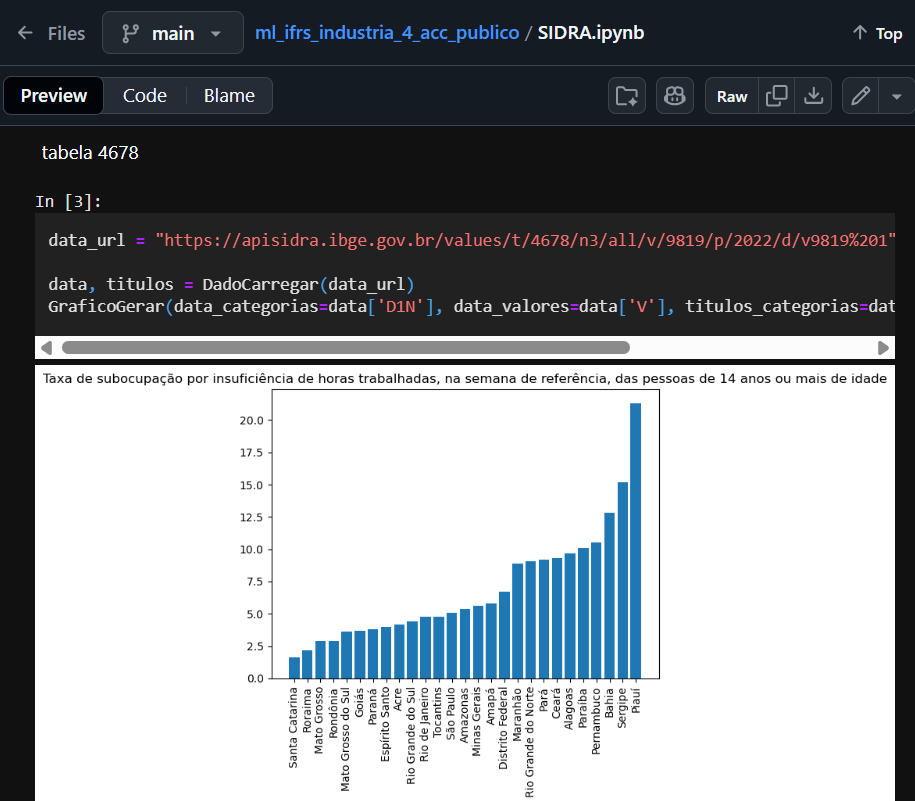
Como fonte de dados foram utilizadas as seguintes tabelas estatísticas da pesquisa PNADC/A:
Para garimpar, polir os dados (ETL-Extract, Transform e Load) e gerar o histograma utilizamos python e panda através de um jupiter notebook .
 Plataformas de computação e ferramentas de análise de dados
Como ferramentas utilizamos a plataforma AWS por disponibilizar
serviços e ambientes prontos tais como:
Plataformas de computação e ferramentas de análise de dados
Como ferramentas utilizamos a plataforma AWS por disponibilizar
serviços e ambientes prontos tais como:
- 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz 2.80 GHz; 16,0 GB (utilizável: 15,7 GB);
- Windows 11 Pro 23H2;
- AWS SageMaker (serviço, disponibiliza toda computação utilizada);
- AWS Glue (serviço, ferramenta de ETL: Extract, transform, load );
- Python 3 (linguagem de programação, disponilizado no AWS Sagemaker);
- Jupiter notebook (web integrated development environment - IDE, disponilizado no AWS Sagemaker);
- Scikit-learn 1.6 (biblioteca de análise de dados predictiva, disponilizado no AWS Sagemaker);
- NumPy 2.2 (biblioteca de computação científica numérica, disponilizado no AWS Sagemaker);
- Matplotlib (biblioteca de visualização, disponilizado no AWS Sagemaker);
- SciPy (biblioteca de algoritmos de computação científica, disponilizado no AWS Sagemaker);